You can run this notebook in a live session ![]() or view it on Github.
or view it on Github.
Implications of verify(dim)#
This demo demonstrates how setting dim in PerfectModelEnsemble.verify() and HindcastEnsemble.verify() alters the research question and prediction skill obtained, especially for spatial fields.
What’s the purpose of dim?
dim is designed the same way as in xarray.Dataset.mean(). A given metric is calculated over dimension dim, i.e. the result does not contain dim anymore. dim can be a string or list of strings.
3 ways to calculate aggregated prediction skill
Spatially aggregate first, then
verifyverifyon each grid point, then aggregate spatiallyverifyover spatial,memberandinitialization directly
# linting
%load_ext nb_black
%load_ext lab_black
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import xarray as xr
import climpred
climpred.set_options(PerfectModel_persistence_from_initialized_lead_0=True)
/home/docs/checkouts/readthedocs.org/user_builds/climpred/conda/latest/lib/python3.10/site-packages/xclim/sdba.py:12: UserWarning: The `xclim.sdba` module has been split into its own package `xsdba`. Users are encouraged to use `xsdba` directly. For the time being, `xclim.sdba` will import `xsdba` to allow for API compatibility. This behaviour may change in the future. For more information, see: https://xsdba.readthedocs.io/en/stable/xclim_migration_guide.html
warnings.warn(
/home/docs/checkouts/readthedocs.org/user_builds/climpred/conda/latest/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
<climpred.options.set_options at 0x744389699300>
sample spatial initialized ensemble data and nomenclature#
We also have some sample output that contains gridded data on MPIOM grid:
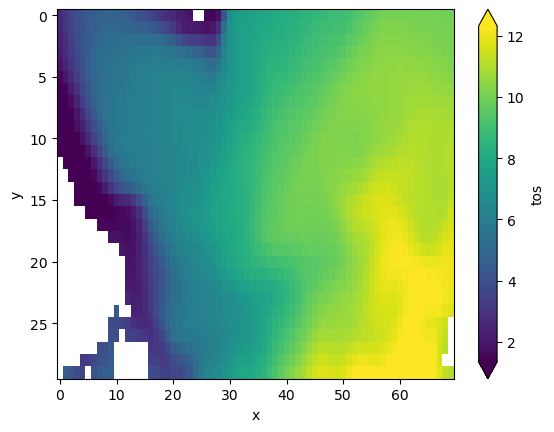
initialized3d: The initialized ensemble dataset withmembers (1, … ,4) denoted by \(m\)inits (initialization years:3014,3061,3175,3237) denoted by \(i\)leadyears (1, …,5) denoted by \(l\).xandj(think as longitude and latitude): spatial dimensions denotes by \(s\).
control3d: The control dataset spanning overtime(3000, …,3049) [not used here].
In PerfectModelEnsemble.verify(), we calculate a \(metric\) on \(data(s,i,m,l)\) containing spatial dimensions \(s\) and ensemble dimension \(i,m,l\) over dimensions \(dim\) denoted by \(metric(data(s,i,m,l), dim)\).
# Sea surface temperature
initialized3d = climpred.tutorial.load_dataset("MPI-PM-DP-3D")
control3d = climpred.tutorial.load_dataset("MPI-control-3D")
v = "tos"
initialized3d["lead"].attrs = {"units": "years"}
# Create climpred PerfectModelEnsemble object.
pm = (
climpred.PerfectModelEnsemble(initialized3d).add_control(control3d)
# .generate_uninitialized() # needed for uninitialized in reference
)
/home/docs/checkouts/readthedocs.org/user_builds/climpred/conda/latest/lib/python3.10/site-packages/climpred/utils.py:198: UserWarning: Assuming annual resolution starting Jan 1st due to numeric inits. Please change ``init`` to a datetime if it is another resolution. We recommend using xr.CFTimeIndex as ``init``, see https://climpred.readthedocs.io/en/stable/setting-up-data.html.
warnings.warn(
/home/docs/checkouts/readthedocs.org/user_builds/climpred/conda/latest/lib/python3.10/site-packages/climpred/utils.py:198: UserWarning: Assuming annual resolution starting Jan 1st due to numeric inits. Please change ``init`` to a datetime if it is another resolution. We recommend using xr.CFTimeIndex as ``init``, see https://climpred.readthedocs.io/en/stable/setting-up-data.html.
warnings.warn(
subselecting North Atlantic#
<matplotlib.collections.QuadMesh at 0x7443403d7cd0>
verify_kwargs = dict(
metric="pearson_r", # 'rmse'
comparison="m2m",
reference=["persistence", "climatology"], # "uninitialized",
skipna=True,
)
dim = ["init", "member"]
spatial_dims = ["x", "y"]
Here, we use the anomaly correlation coefficient climpred.metrics._pearson_r(). Also try root-mean-squared-error climpred.metrics._rmse().
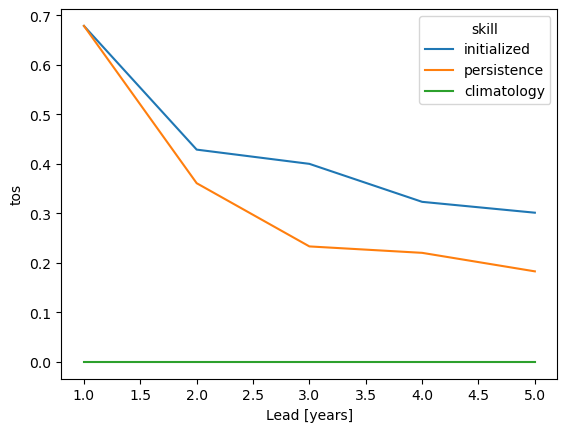
Spatial aggregate first, then verify#
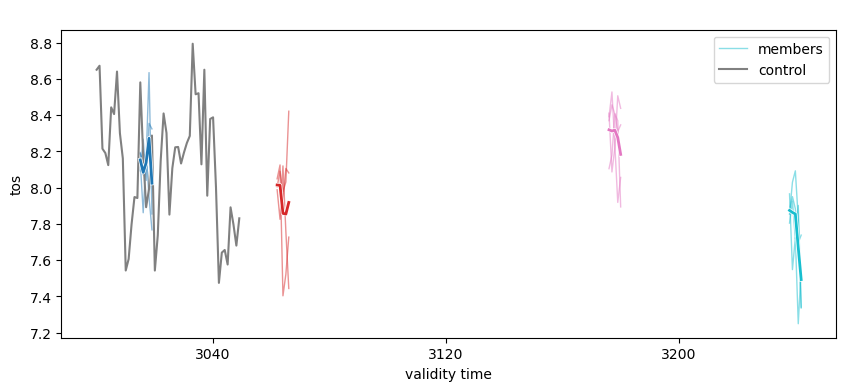
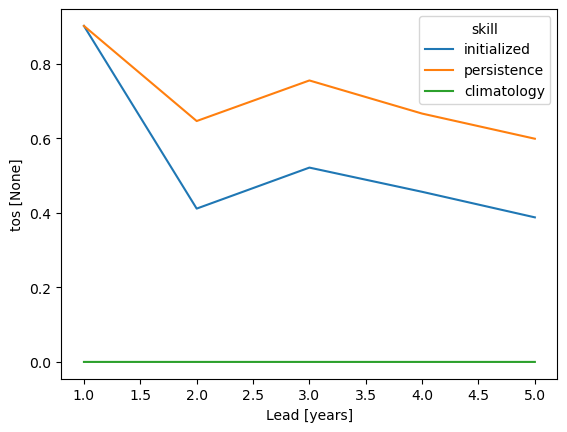
Here, we first average the raw ensemble data over the spatial_dims, i.e. creating North Atlantic averaged SST timeseries. On this timeseries, we calculate the prediction skill with PerfectModelEnsemble.verify().
\(skill(l) = metric(\overline{data(s,i,m,l)}^s, i, m)\)
where \(\overline{data}^{dim}\) represents the average of \(data\) over dimension \(dim\)
This approach answers the question: “What’s the prediction skill of SSTs, which were averaged before over the North Atlantic? What is the skill at predicting average [metric] in [domain]?”
Used in Pohlmann et al. [2004], Spring and Ilyina [2020], Séférian et al. [2018].
Recommended by Goddard et al. [2013] section 2.1.4:
“We advocate verifying on at least two spatial scales: (1) the observational grid scales to which the model data is interpolated, and (2) smoothed or regional scales. The latter can be accomplished by suitable spatial-smoothing algorithms, such as simple averages or spectral filters.”
pm_aggregated = pm.mean(spatial_dims)
# see the NA SST timeseries
pm_aggregated.plot(show_members=True)
<Axes: title={'center': ' '}, xlabel='validity time', ylabel='tos'>
pm_aggregated_skill = pm_aggregated.verify(dim=dim, **verify_kwargs)
pm_aggregated_skill[v].plot(hue="skill")
/home/docs/checkouts/readthedocs.org/user_builds/climpred/conda/latest/lib/python3.10/site-packages/climpred/classes.py:1643: UserWarning: Calculate persistence from lead=1 instead of lead=0 (recommended).
warnings.warn(
[<matplotlib.lines.Line2D at 0x74433b6470d0>,
<matplotlib.lines.Line2D at 0x74433b647220>,
<matplotlib.lines.Line2D at 0x74433b6461d0>]
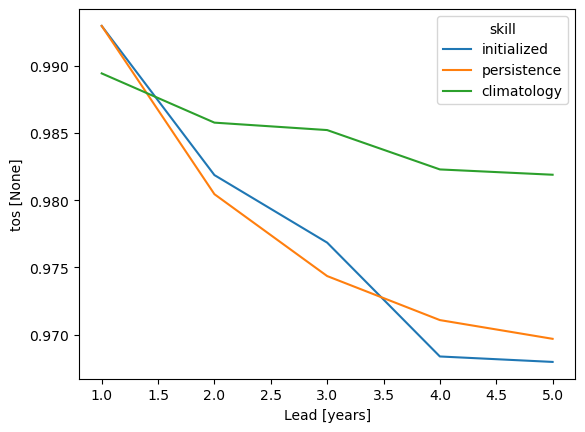
verify on each grid point, then aggregate#
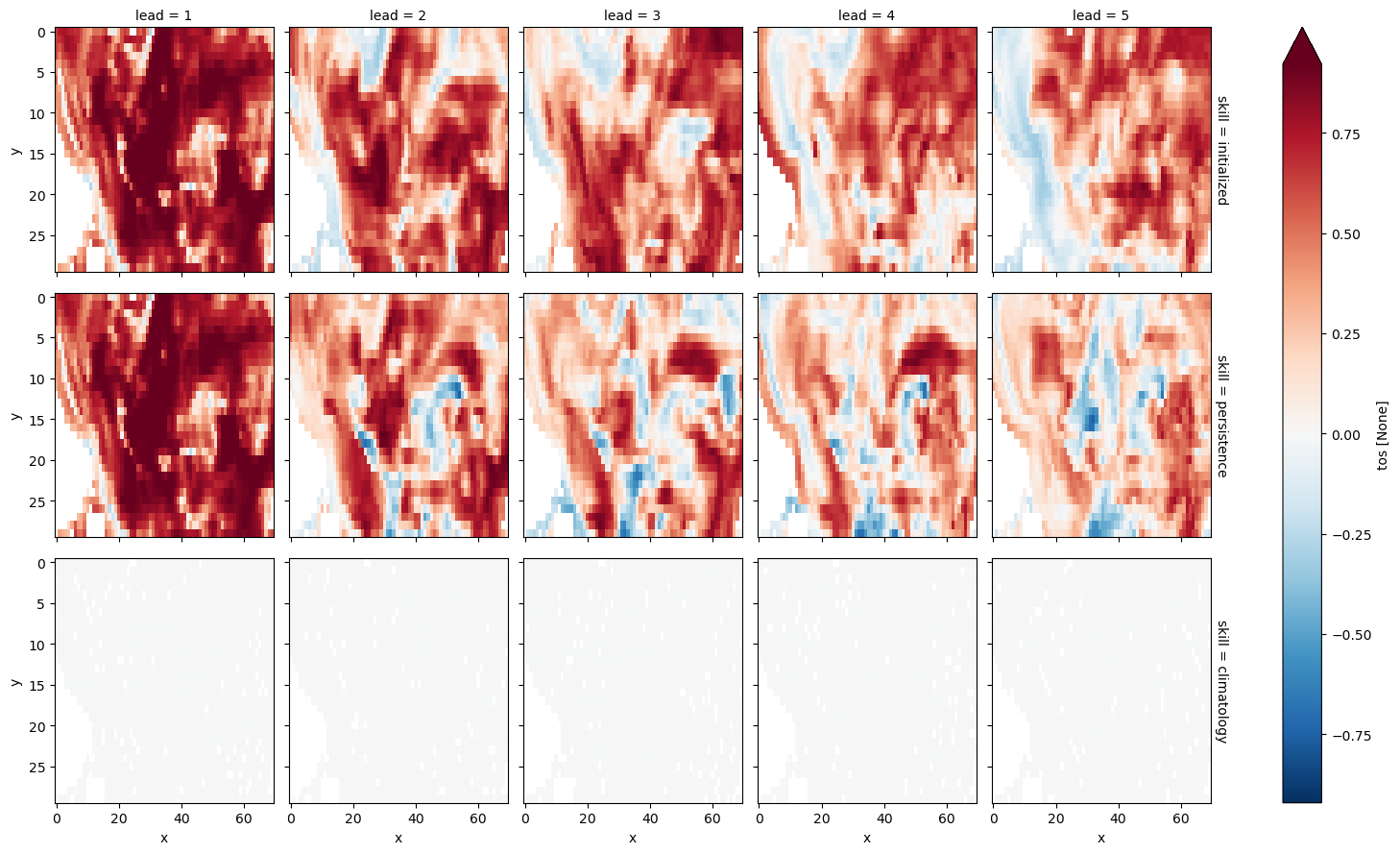
Here, we first calculate prediction skill with PerfectModelEnsemble.verify() and then average the SST skill over the North Atlantic region.
\(skill(l) = \overline{metric(data(s,i,m,l), i, m)}^s\)
This approach answers the question: “What’s the prediction skill of North Altantic SST grid points averaged afterwards? What is the average skill of predicting [metric] in [domain]?”
Used in Frölicher et al. [2020].
grid_point_skill = pm.verify(dim=dim, **verify_kwargs)
grid_point_skill[v].plot(col="lead", row="skill", robust=True, yincrease=False)
/home/docs/checkouts/readthedocs.org/user_builds/climpred/conda/latest/lib/python3.10/site-packages/climpred/classes.py:1643: UserWarning: Calculate persistence from lead=1 instead of lead=0 (recommended).
warnings.warn(
<xarray.plot.facetgrid.FacetGrid at 0x74433b5bac80>
grid_point_skill_aggregated = grid_point_skill.mean(spatial_dims)
grid_point_skill_aggregated[v].plot(hue="skill")
plt.show()
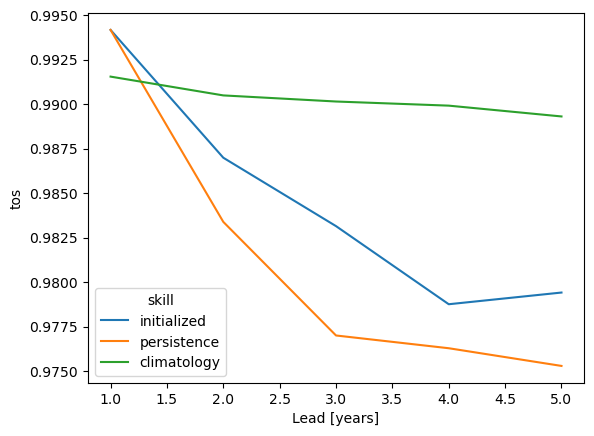
verify over each grid point, member and initialization directly#
Here, we directly calculate prediction skill with PerfectModelEnsemble.verify() over spatial_dims, member and init.
\(skill(l) = metric(data(s,i,m,l), s, i, m)\)
This approach answers the question: What’s the prediction skill of the North Atlantic SST pattern (calculated over all members and inits)? What is the spatial skill of predicting [metric] over [domain]?
Used in Becker et al. [2014], Fransner et al. [2020].
skill_all_at_once = pm.verify(dim=dim + spatial_dims, **verify_kwargs)
skill_all_at_once[v].plot(hue="skill")
plt.show()
/home/docs/checkouts/readthedocs.org/user_builds/climpred/conda/latest/lib/python3.10/site-packages/climpred/classes.py:1643: UserWarning: Calculate persistence from lead=1 instead of lead=0 (recommended).
warnings.warn(
This approach yields very similar results to first calculating prediction skill over the spatial_dims, i.e. calculating a pattern correlation and then doing a mean over ensemble dimensions member and init.
\(skill(l) = \overline{metric(data(s,i,m,l), s)}^{i,m}\)
skill_spatial_then_ensemble_mean = pm.verify(dim=spatial_dims, **verify_kwargs).mean(
dim
)
skill_spatial_then_ensemble_mean[v].plot(hue="skill")
plt.show()
/home/docs/checkouts/readthedocs.org/user_builds/climpred/conda/latest/lib/python3.10/site-packages/climpred/classes.py:1643: UserWarning: Calculate persistence from lead=1 instead of lead=0 (recommended).
warnings.warn(
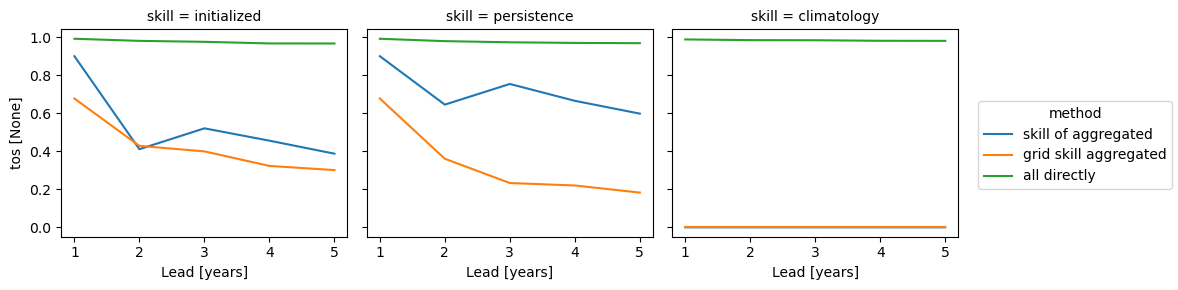
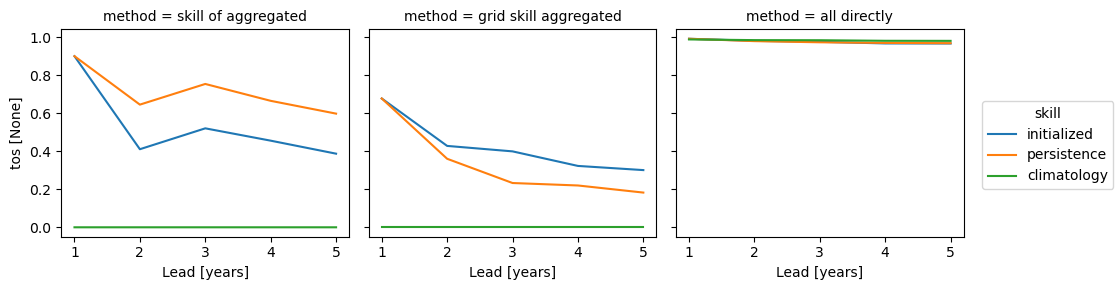
Summary#
The three approaches yield very different results based on the dim keyword. Make you choose dim according to the question you want to answer. And always compare your initialized skill to the reference skills, which also heavily depend on dim. The small details matter a lot!
skills = xr.concat(
[pm_aggregated_skill, grid_point_skill_aggregated, skill_all_at_once], "method"
).assign_coords(method=["skill of aggregated", "grid skill aggregated", "all directly"])
skills[v].plot(hue="method", col="skill")
<xarray.plot.facetgrid.FacetGrid at 0x74433aa44d60>
skills[v].plot(col="method", hue="skill")
<xarray.plot.facetgrid.FacetGrid at 0x74433a7b0370>
References#
Emily Becker, Huug van den Dool, and Qin Zhang. Predictability and Forecast Skill in NMME. Journal of Climate, 27(15):5891–5906, August 2014. doi:10.1175/JCLI-D-13-00597.1.
Filippa Fransner, François Counillon, Ingo Bethke, Jerry Tjiputra, Annette Samuelsen, Aleksi Nummelin, and Are Olsen. Ocean Biogeochemical Predictions—Initialization and Limits of Predictability. Frontiers in Marine Science, 2020. doi:10/gg22rr.
Thomas L. Frölicher, Luca Ramseyer, Christoph C. Raible, Keith B. Rodgers, and John Dunne. Potential predictability of marine ecosystem drivers. Biogeosciences, 17(7):2061–2083, April 2020. doi:10/ggr9mb.
L. Goddard, A. Kumar, A. Solomon, D. Smith, G. Boer, P. Gonzalez, V. Kharin, W. Merryfield, C. Deser, S. J. Mason, B. P. Kirtman, R. Msadek, R. Sutton, E. Hawkins, T. Fricker, G. Hegerl, C. a. T. Ferro, D. B. Stephenson, G. A. Meehl, T. Stockdale, R. Burgman, A. M. Greene, Y. Kushnir, M. Newman, J. Carton, I. Fukumori, and T. Delworth. A verification framework for interannual-to-decadal predictions experiments. Climate Dynamics, 40(1-2):245–272, January 2013. doi:10/f4jjvf.
Holger Pohlmann, Michael Botzet, Mojib Latif, Andreas Roesch, Martin Wild, and Peter Tschuck. Estimating the Decadal Predictability of a Coupled AOGCM. Journal of Climate, 17(22):4463–4472, November 2004. doi:10/d2qf62.
Aaron Spring and Tatiana Ilyina. Predictability Horizons in the Global Carbon Cycle Inferred From a Perfect-Model Framework. Geophysical Research Letters, 47(9):e2019GL085311, 2020. doi:10/ggtbv2.
Roland Séférian, Sarah Berthet, and Matthieu Chevallier. Assessing the Decadal Predictability of Land and Ocean Carbon Uptake. Geophysical Research Letters, March 2018. doi:10/gdb424.