You can run this notebook in a live session ![]() or view it on Github.
or view it on Github.
Verification Alignment#
A forecast is verified by comparing a set of initializations at a given lead to observations over some window of time. However, there are a few ways to decide which initializations or verification window to use in this alignment.
One must pass the keyword alignment=... to the HindcastEnsemble.verify() method to set the behavior for aligning forecasts with the verification product. Note that the alignment decision only matters for HindcastEnsemble. PerfectModelEnsemble are perfectly time-aligned by design, equating to our "same_inits" keyword.
The available keywords for hindcast alignment are:
"same_inits": Use a common set of initializations that verify across all leads. This ensures that there is no bias in the result due to the state of the system for the given initializations."same_verifs": Use a common verification window across all leads. This ensures that there is no bias in the result due to the observational period being verified against."maximize": Use all available initializations at each lead that verify against the observations provided. This changes both the set of initializations and the verification window used at each lead.
# linting
%load_ext nb_black
%load_ext lab_black
from climpred import HindcastEnsemble
from climpred.tutorial import load_dataset
from esmtools.stats import rm_trend
import matplotlib.pyplot as plt
plt.style.use("fivethirtyeight")
%matplotlib inline
import numpy as np
import warnings
# Supress datetime warnings for this page.
warnings.filterwarnings("ignore")
def create_hindcast_object():
"""Loads in example data from CESM-DPLE and ERSST observations and detrends."""
hind = load_dataset("CESM-DP-SST")["SST"]
verif = load_dataset("ERSST")["SST"]
# Bias-correct over same period as CESM-DPLE.
verif = verif - verif.sel(time=slice(1964, 2014)).mean("time")
# Remove linear trend.
hind_dt = rm_trend(hind, dim="init").rename("SST")
verif_dt = rm_trend(verif, dim="time").rename("SST")
# Create `HindcastEnsemble` object from `climpred`.
hindcast = HindcastEnsemble(hind)
hindcast = hindcast.add_observations(verif)
hindcast_dt = HindcastEnsemble(hind_dt)
hindcast_dt = hindcast_dt.add_observations(verif_dt)
return hindcast, hindcast_dt
hindcast, hindcast_dt = create_hindcast_object()
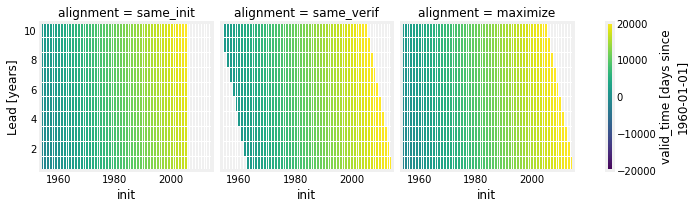
The user can simply change the alignment strategy by passing in the keyword alignment=.... HindcastEnsemble.plot_alignment() shows valid_time dates that are verified against observations.
hindcast.plot_alignment(edgecolor="w")
<xarray.plot.facetgrid.FacetGrid at 0x148fc5c10>
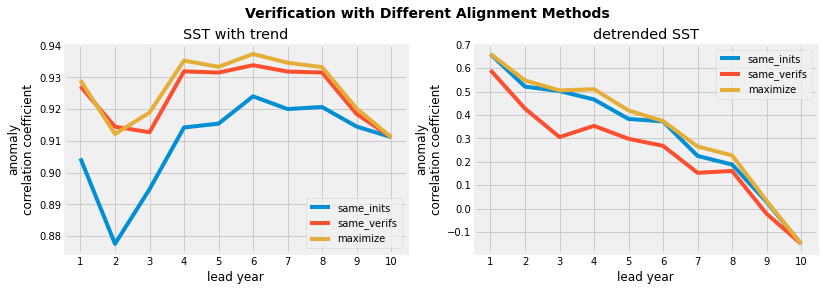
Note that the choice of alignment strategy changes the lead-dependent metric results.
f, axs = plt.subplots(ncols=2, figsize=(12, 4), sharex=True)
for alignment in ["same_inits", "same_verifs", "maximize"]:
hindcast.verify(metric="acc", comparison="e2o", dim="init", alignment=alignment)[
"SST"
].plot(label=alignment, ax=axs[0])
hindcast_dt.verify(metric="acc", comparison="e2o", dim="init", alignment=alignment)[
"SST"
].plot(label=alignment, ax=axs[1])
axs[0].legend()
axs[1].legend()
axs[0].set(
ylabel="anomaly\ncorrelation coefficient",
xlabel="lead year",
xticks=np.arange(1, 11),
title="SST with trend",
)
axs[1].set(
ylabel="anomaly\ncorrelation coefficient", xlabel="lead year", title="detrended SST"
)
f.suptitle("Verification with Different Alignment Methods", fontsize=14, weight="bold")
plt.subplots_adjust(top=0.85)
plt.show()
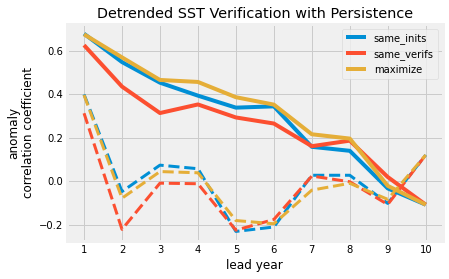
These alignment keywords also extend to reference forecasts (e.g. reference="persistence"), which uses the identical set of initializations (and alignment strategy) in its computation. Below, the dashed lines represent the persistence forecast for the given alignment strategy, while the solid lines denote the initialized anomaly correlation coefficient (as in the above plots).
COLORS = ["#008FD5", "#FC4F30", "#E5AE38"]
f, axs = plt.subplots()
for alignment, color in zip(["same_inits", "same_verifs", "maximize"], COLORS):
result = hindcast_dt.verify(
metric="acc",
reference="persistence",
comparison="e2o",
dim="init",
alignment=alignment,
)
result.sel(skill="initialized").SST.plot(label=alignment, color=color)
result.sel(skill="persistence").SST.plot(linestyle="--", color=color, lw=3)
axs.set(
ylabel="anomaly\ncorrelation coefficient",
xlabel="lead year",
xticks=np.arange(1, 11),
title="Detrended SST Verification with Persistence",
)
plt.legend()
plt.show()
We’ll be using the same example data as above. climpred will be aligning the following initialization and verification dates:
print(f"initialization dates: \n{hindcast.get_initialized().init.to_index()}")
initialization dates:
CFTimeIndex([1954-01-01 00:00:00, 1955-01-01 00:00:00, 1956-01-01 00:00:00,
1957-01-01 00:00:00, 1958-01-01 00:00:00, 1959-01-01 00:00:00,
1960-01-01 00:00:00, 1961-01-01 00:00:00, 1962-01-01 00:00:00,
1963-01-01 00:00:00, 1964-01-01 00:00:00, 1965-01-01 00:00:00,
1966-01-01 00:00:00, 1967-01-01 00:00:00, 1968-01-01 00:00:00,
1969-01-01 00:00:00, 1970-01-01 00:00:00, 1971-01-01 00:00:00,
1972-01-01 00:00:00, 1973-01-01 00:00:00, 1974-01-01 00:00:00,
1975-01-01 00:00:00, 1976-01-01 00:00:00, 1977-01-01 00:00:00,
1978-01-01 00:00:00, 1979-01-01 00:00:00, 1980-01-01 00:00:00,
1981-01-01 00:00:00, 1982-01-01 00:00:00, 1983-01-01 00:00:00,
1984-01-01 00:00:00, 1985-01-01 00:00:00, 1986-01-01 00:00:00,
1987-01-01 00:00:00, 1988-01-01 00:00:00, 1989-01-01 00:00:00,
1990-01-01 00:00:00, 1991-01-01 00:00:00, 1992-01-01 00:00:00,
1993-01-01 00:00:00, 1994-01-01 00:00:00, 1995-01-01 00:00:00,
1996-01-01 00:00:00, 1997-01-01 00:00:00, 1998-01-01 00:00:00,
1999-01-01 00:00:00, 2000-01-01 00:00:00, 2001-01-01 00:00:00,
2002-01-01 00:00:00, 2003-01-01 00:00:00, 2004-01-01 00:00:00,
2005-01-01 00:00:00, 2006-01-01 00:00:00, 2007-01-01 00:00:00,
2008-01-01 00:00:00, 2009-01-01 00:00:00, 2010-01-01 00:00:00,
2011-01-01 00:00:00, 2012-01-01 00:00:00, 2013-01-01 00:00:00,
2014-01-01 00:00:00, 2015-01-01 00:00:00, 2016-01-01 00:00:00,
2017-01-01 00:00:00],
dtype='object',
length=64,
calendar='proleptic_gregorian',
freq='AS-JAN')
print(f"verification dates: \n{hindcast.get_observations().time.to_index()}")
verification dates:
CFTimeIndex([1955-01-01 00:00:00, 1956-01-01 00:00:00, 1957-01-01 00:00:00,
1958-01-01 00:00:00, 1959-01-01 00:00:00, 1960-01-01 00:00:00,
1961-01-01 00:00:00, 1962-01-01 00:00:00, 1963-01-01 00:00:00,
1964-01-01 00:00:00, 1965-01-01 00:00:00, 1966-01-01 00:00:00,
1967-01-01 00:00:00, 1968-01-01 00:00:00, 1969-01-01 00:00:00,
1970-01-01 00:00:00, 1971-01-01 00:00:00, 1972-01-01 00:00:00,
1973-01-01 00:00:00, 1974-01-01 00:00:00, 1975-01-01 00:00:00,
1976-01-01 00:00:00, 1977-01-01 00:00:00, 1978-01-01 00:00:00,
1979-01-01 00:00:00, 1980-01-01 00:00:00, 1981-01-01 00:00:00,
1982-01-01 00:00:00, 1983-01-01 00:00:00, 1984-01-01 00:00:00,
1985-01-01 00:00:00, 1986-01-01 00:00:00, 1987-01-01 00:00:00,
1988-01-01 00:00:00, 1989-01-01 00:00:00, 1990-01-01 00:00:00,
1991-01-01 00:00:00, 1992-01-01 00:00:00, 1993-01-01 00:00:00,
1994-01-01 00:00:00, 1995-01-01 00:00:00, 1996-01-01 00:00:00,
1997-01-01 00:00:00, 1998-01-01 00:00:00, 1999-01-01 00:00:00,
2000-01-01 00:00:00, 2001-01-01 00:00:00, 2002-01-01 00:00:00,
2003-01-01 00:00:00, 2004-01-01 00:00:00, 2005-01-01 00:00:00,
2006-01-01 00:00:00, 2007-01-01 00:00:00, 2008-01-01 00:00:00,
2009-01-01 00:00:00, 2010-01-01 00:00:00, 2011-01-01 00:00:00,
2012-01-01 00:00:00, 2013-01-01 00:00:00, 2014-01-01 00:00:00,
2015-01-01 00:00:00],
dtype='object',
length=61,
calendar='proleptic_gregorian',
freq='AS-JAN')
We use the standard python library logging to log the initializations and verification dates used in alignment at each lead. The user can check these logs to ensure that the expected initializations and verification dates are being retained. See the logging section on this page for more details.
import logging
# Print log to screen with initializations and verification dates.
logger = logging.getLogger()
logger.setLevel(logging.INFO)
Same Verification Dates#
alignment="same_verifs"
The same_verifs alignment finds a set of verification dates that can be verified against over all leads. It also requires that the verification data have an observation at each initialization being retained. This is so that the reference forecast, such as persistence, uses an identical set of initializations in deriving its forecast. Notice in the logger output that a common set of verification dates spanning 1965-2015 are used, while the initialization window slides one year at each lead.
alignment="same_verifs" used in [Boer et al., 2016, Hawkins et al., 2014, Smith et al., 2013].
skill = hindcast.verify(
metric="acc", comparison="e2o", dim="init", alignment="same_verifs"
)
INFO:root:initialized | lead: 01 | inits: 1963-01-01 00:00:00-2014-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 02 | inits: 1962-01-01 00:00:00-2013-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 03 | inits: 1961-01-01 00:00:00-2012-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 04 | inits: 1960-01-01 00:00:00-2011-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 05 | inits: 1959-01-01 00:00:00-2010-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 06 | inits: 1958-01-01 00:00:00-2009-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 07 | inits: 1957-01-01 00:00:00-2008-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 08 | inits: 1956-01-01 00:00:00-2007-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 09 | inits: 1955-01-01 00:00:00-2006-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 10 | inits: 1954-01-01 00:00:00-2005-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
Here, we include a figure of a simpler alignment case with annual initializations from 1990 through 2000 and three lead years. We verify this hypothetical initialized ensemble against a product that spans 1995 through 2002.
Two conditions must be met when selecting the verification window:
There must be a union between the initialization dates and verification dates. This is represented by the black vertical lines in the top panel below, which leave out 1990-1994 initializations since there aren’t observations before 1995. This logic exists so that any reference forecasts (e.g. a persistence forecast) use an identical set of initializations as the initialized forecast.
A given verification time must exist across all leads. This is to ensure that at each lead, the entire set of chosen verification dates can be verified against. This is represented by diagonals in the top panel below (and the dashed black lines). Without the first stipulation, this would set the verification window at 1995-2001.
This leaves us with a verification window of [1998, 1999, 2000, 2001] which can be verified against across all leads (and have a complimentary persistence forecast with the same set of initializations used at each lead).

Same Initializations#
alignment="same_inits"
The same_inits alignment finds a set of initializations that can verify over all leads. It also requires that the verification data have an observation at each initialization being retained. This is so that the reference forecast, such as persistence, uses an identical set of initializations in deriving its forecast. Notice in the logger output that a common set of initializations spanning 1955-2005 are used, while the verification window slides one year at each lead.
alignment="same_inits" used in [Marotzke et al., 2016].
skill = hindcast.verify(
metric="acc", comparison="e2o", dim="init", alignment="same_inits"
)
INFO:root:initialized | lead: 01 | inits: 1954-01-01 00:00:00-2005-01-01 00:00:00 | verifs: 1955-01-01 00:00:00-2006-01-01 00:00:00
INFO:root:initialized | lead: 02 | inits: 1954-01-01 00:00:00-2005-01-01 00:00:00 | verifs: 1956-01-01 00:00:00-2007-01-01 00:00:00
INFO:root:initialized | lead: 03 | inits: 1954-01-01 00:00:00-2005-01-01 00:00:00 | verifs: 1957-01-01 00:00:00-2008-01-01 00:00:00
INFO:root:initialized | lead: 04 | inits: 1954-01-01 00:00:00-2005-01-01 00:00:00 | verifs: 1958-01-01 00:00:00-2009-01-01 00:00:00
INFO:root:initialized | lead: 05 | inits: 1954-01-01 00:00:00-2005-01-01 00:00:00 | verifs: 1959-01-01 00:00:00-2010-01-01 00:00:00
INFO:root:initialized | lead: 06 | inits: 1954-01-01 00:00:00-2005-01-01 00:00:00 | verifs: 1960-01-01 00:00:00-2011-01-01 00:00:00
INFO:root:initialized | lead: 07 | inits: 1954-01-01 00:00:00-2005-01-01 00:00:00 | verifs: 1961-01-01 00:00:00-2012-01-01 00:00:00
INFO:root:initialized | lead: 08 | inits: 1954-01-01 00:00:00-2005-01-01 00:00:00 | verifs: 1962-01-01 00:00:00-2013-01-01 00:00:00
INFO:root:initialized | lead: 09 | inits: 1954-01-01 00:00:00-2005-01-01 00:00:00 | verifs: 1963-01-01 00:00:00-2014-01-01 00:00:00
INFO:root:initialized | lead: 10 | inits: 1954-01-01 00:00:00-2005-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
Here, we include a figure of a simpler alignment case with annual initializations from 1990 through 2000 and three lead years. We verify this hypothetical initialized ensemble against a product that spans 1995 through 2002.
Two conditions must be met to retain the initializations for verification:
There must be an observation in the verification data for the given initialization. In combination with (1), initializations 1990 through 1994 are left out. This logic exists so that any reference forecast (e.g. a persistence forecast) use an identical set of initializations as the initialized forecast.
All forecasted times (i.e., initialization + lead year) for a given initialization must be contained in the verification data. Schematically, this means that there must be a union between a column in the top panel and the time series in the bottom panel. The 2000 initialization below is left out since the verification data does not contain 2003.
This leaves us with initializations [1995, 1996, …, 1999] which can verify against the observations at all three lead years.

Maximize Degrees of Freedom#
alignment="maximize"
The maximize alignment verifies against every available observation at each lead. This means that both the initializations and verification dates could be different at each lead. It also requires that the verification data have an observation at each initialization being retained. This is so that the reference forecast, such as persistence, uses an identical set of initializations in deriving its forecast.
Notice in the logger output that the initialization window shrinks from 1955-2014 (N=60) at lead year 1 to 1955-2005 (N=51) at lead year 10. Similarly, the verification window spans 1956-2015 at lead year 1 and 1965-2015 at lead year 10. However, using the other two alignment strategies (same_verifs and same_inits), there is a fixed N=51 to ensure constant initializations or verification dates, while the number of samples is extended to as high as 60 with this alignment strategy.
alignment="maximize" used in [Yeager et al., 2018].
skill = hindcast.verify(
metric="acc", comparison="e2o", dim="init", alignment="maximize"
)
INFO:root:initialized | lead: 01 | inits: 1954-01-01 00:00:00-2014-01-01 00:00:00 | verifs: 1955-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 02 | inits: 1954-01-01 00:00:00-2013-01-01 00:00:00 | verifs: 1956-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 03 | inits: 1954-01-01 00:00:00-2012-01-01 00:00:00 | verifs: 1957-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 04 | inits: 1954-01-01 00:00:00-2011-01-01 00:00:00 | verifs: 1958-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 05 | inits: 1954-01-01 00:00:00-2010-01-01 00:00:00 | verifs: 1959-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 06 | inits: 1954-01-01 00:00:00-2009-01-01 00:00:00 | verifs: 1960-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 07 | inits: 1954-01-01 00:00:00-2008-01-01 00:00:00 | verifs: 1961-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 08 | inits: 1954-01-01 00:00:00-2007-01-01 00:00:00 | verifs: 1962-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 09 | inits: 1954-01-01 00:00:00-2006-01-01 00:00:00 | verifs: 1963-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 10 | inits: 1954-01-01 00:00:00-2005-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
Here, we include a figure of a simpler alignment case with annual initializations from 1990 through 2000 and three lead years. We verify this hypothetical initialized ensemble against a product that spans 1995 through 2002.
Two conditions must be met when selecting initializations/verifications at each lead:
There must be a union between the initialization dates and verification dates. This is represented by the black vertical lines in the top panel below, which leave out 1990-1994 initializations since there aren’t observations before 1995. This logic exists so that any reference forecasts (e.g. a persistence forecast) use an identical set of initializations as the initialized forecast.
The selected initializations must verify with the provided observations for the given lead. This is shown by the hatching in the figure below. The 2000 initialization is left out at lead year 3 since there is no observation for 2003.
This leaves us with the following alignment:
LY1 initializations: [1995, 1996, 1997, 1998, 1999, 2000]
LY2 initializations: [1995, 1996, 1997, 1998, 1999, 2000]
LY3 initializations: [1995, 1996, 1997, 1998, 1999]

Logging#
climpred uses the standard library logging to store the initializations and verification dates used at each lead for a given computation. This is used internally for testing, but more importantly, can be activated by the user so they can be sure of how computations are being done.
To see the log interactively, e.g. while working in Jupyter notebooks or on the command line use the following:
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
skill = hindcast.verify(
metric="acc", comparison="e2o", dim="init", alignment="same_verifs"
)
INFO:root:initialized | lead: 01 | inits: 1963-01-01 00:00:00-2014-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 02 | inits: 1962-01-01 00:00:00-2013-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 03 | inits: 1961-01-01 00:00:00-2012-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 04 | inits: 1960-01-01 00:00:00-2011-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 05 | inits: 1959-01-01 00:00:00-2010-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 06 | inits: 1958-01-01 00:00:00-2009-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 07 | inits: 1957-01-01 00:00:00-2008-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 08 | inits: 1956-01-01 00:00:00-2007-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 09 | inits: 1955-01-01 00:00:00-2006-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
INFO:root:initialized | lead: 10 | inits: 1954-01-01 00:00:00-2005-01-01 00:00:00 | verifs: 1964-01-01 00:00:00-2015-01-01 00:00:00
The INFO level reports the minimum and maximum bounds for initializations and verification dates. To see every single initialization and verification date used, set the level to DEBUG.
References#
G. J. Boer, D. M. Smith, C. Cassou, F. Doblas-Reyes, G. Danabasoglu, B. Kirtman, Y. Kushnir, M. Kimoto, G. A. Meehl, R. Msadek, W. A. Mueller, K. E. Taylor, F. Zwiers, M. Rixen, Y. Ruprich-Robert, and R. Eade. The Decadal Climate Prediction Project (DCPP) contribution to CMIP6. Geosci. Model Dev., 9(10):3751–3777, October 2016. doi:10/f89qdf.
Ed Hawkins, Buwen Dong, Jon Robson, Rowan Sutton, and Doug Smith. The Interpretation and Use of Biases in Decadal Climate Predictions. Journal of Climate, 27(8):2931–2947, January 2014. doi:10/f5w2xr.
Jochem Marotzke, Wolfgang A. Müller, Freja S. E. Vamborg, Paul Becker, Ulrich Cubasch, Hendrik Feldmann, Frank Kaspar, Christoph Kottmeier, Camille Marini, Iuliia Polkova, Kerstin Prömmel, Henning W. Rust, Detlef Stammer, Uwe Ulbrich, Christopher Kadow, Armin Köhl, Jürgen Kröger, Tim Kruschke, Joaquim G. Pinto, Holger Pohlmann, Mark Reyers, Marc Schröder, Frank Sienz, Claudia Timmreck, and Markus Ziese. MiKlip: A National Research Project on Decadal Climate Prediction. Bulletin of the American Meteorological Society, 97(12):2379–2394, June 2016. doi:10/gddfck.
Doug M. Smith, Adam A. Scaife, George J. Boer, Mihaela Caian, Francisco J. Doblas-Reyes, Virginie Guemas, Ed Hawkins, Wilco Hazeleger, Leon Hermanson, Chun Kit Ho, Masayoshi Ishii, Viatcheslav Kharin, Masahide Kimoto, Ben Kirtman, Judith Lean, Daniela Matei, William J. Merryfield, Wolfgang A. Müller, Holger Pohlmann, Anthony Rosati, Bert Wouters, and Klaus Wyser. Real-time multi-model decadal climate predictions. Climate Dynamics, 41(11-12):2875–2888, December 2013. doi:10/f5g2rz.
S. G. Yeager, G. Danabasoglu, N. Rosenbloom, W. Strand, S. Bates, G. Meehl, A. Karspeck, K. Lindsay, M. C. Long, H. Teng, and N. S. Lovenduski. Predicting near-term changes in the Earth System: A large ensemble of initialized decadal prediction simulations using the Community Earth System Model. Bulletin of the American Meteorological Society, March 2018. doi:10/gddfcs.