What’s New#
climpred v2.7.0 (unreleased)#
New Features#
Documentation is now machine-readable for AI agents and LLM tools. The sphinx-llm extension auto-generates
llms.txt,llms-full.txtand a markdown version of every page (llms.txt standard) during the docs build, published at e.g. https://climpred.readthedocs.io/en/latest/llms.txt. Documentation breadcrumbs were added toclimpred/__init__.pypointing humans and agents to the docs,llms.txt,AGENTS.mdand the agent skill. Aaron SpringAdded new .agents/skills/climpred-forecast-verification/ skill for AI coding agents (e.g., Claude Code, OpenCode). Includes SKILL.md with core concepts, classes, methods, and workflows, plus reference documentation for metrics, comparisons, bias removal, and data setup. (GH910) Aaron Spring
PredictionEnsemble.smooth()gained a newdropkeyword. WhenTrueand a temporalleadsmoothing is applied, the resulting overlapping rolling windows are subsampled to non-overlapping windows (e.g.smooth({"lead": 3}, drop=True)yields leads"1-3", "4-6", "7-9"instead of"1-3", "2-4", ..., "8-10").lead_centernow also carrieslong_nameandunitsattributes after smoothing and verification. Aaron Spring
Internals/Minor Fixes#
Dropped support for Python 3.9 (EOL October 2025). Minimum supported Python is now 3.10. (GH919, GH920) Aaron Spring
HindcastEnsemble.smooth()andPerfectModelEnsemble.smooth()propagate theleadunitsattribute onto thelead_centercoordinate that is added during verification of temporally smoothed ensembles. Aaron SpringHindcastEnsemble.plot_alignment()now raises a clear error message when there is no overlap between hindcastvalid_timeand verificationtime, instead of a crypticValueErroraboutCFTimeIndexambiguity. (GH912, GH921) Aaron Spring
climpred v2.6.0 (2026-02-19)#
New Features#
The climpred code base has been updated to better support modern versions of xarray (>=2024.5.0), pytest (>=8.0.0), as well as Python 3.13. Aaron Spring, Trevor James Smith
Required xskillscore version has been updated to 0.0.29. This version maintains Python 3.9 support and addresses a few small regressions introduced in version 0.0.27. Furthermore now numpy and pandas are unpinned. Aaron Spring, Trevor James Smith
Internals/Minor Fixes#
Updated pre-commit and GitHub CI hooks to more modern versions. (GH866, GH867) Trevor James Smith
Updated several documentation and CI-related configurations to help with security hardening and maintainability. (GH870) Trevor James Smith
Dependency updates to better synchronize conda and pip installation environments. (GH870) Trevor James Smith
Climatology reference forecast of
pearson_rmetric isn’t tested to be non-NaN anymore. (GH884) Aaron SpringHindcastEnsemble.remove_bias()keeps attrs with xarray>=2025.11. (GH885, GH886) Aaron Springpytest-lazy-fixture (abandoned) has been replaced by pytest-lazy-fixtures (maintained fork). (GH870) Trevor James Smith
GitHub Workflows have been adjusted to test against Python 3.13, as well as test pip-based environments. (GH870) Trevor James Smith
Replaced all assert statements found outside of the testing code with appropriate exceptions to be handled. (GH870) Trevor James Smith
Use ty instead of mypy. (GH888, GH896) Aaron Spring
climpred is now tested against macOS and Windows platforms on GitHub Workflows. (GH902) Trevor James Smith
Updated dependencies to support numpy`version 2.x and `pandas version 3.0: numpy>=2.0.0, pandas>=2.0, xarray>=2024.5.0, xskillscore>=0.0.29. Fixed timedelta dtype detection using
np.issubdtype()and added error handling for corrupted XML downloads. (GH904) Aaron Springclimpred metadata now adheres to PEP 639. (GH906) Trevor James Smith
climpred v2.5.0 (2024-07-05)#
Internals/Minor Fixes#
Fixed some issues with the documentation build to address rendering errors and reduce the number of warnings on ReadTheDocs. (GH843) Trevor James Smith
Fixed some issues with the typing hints of classes functions. (GH850) Trevor James Smith
Fixed several issues with incompatible dependency configurations in the CI and addressed a few deprecations. (GH861) Trevor James Smith
climpred has adopted PEP 621 for specifying project metadata. (GH862) Trevor James Smith
climpred now uses the src layout for the package file structure. (GH862) Trevor James Smith
Drop
python<=3.8support. (GH862) Trevor James Smith
climpred v2.4.0 (2023-11-09)#
Internals/Minor Fixes#
Fix broken GEFS link (GH807) Trevor Gamblin
New metric
_meMean Error asmetric='me': (GH826, GH827) Aaron SpringUnpin
xarrayandxclimand update package health. (GH815, feedstock-issue, GH831, GH832) Aaron Spring, Trevor James Smith, Mathias HauserAdd Trusted Publishing and leverage GitHub deployment environments. (GH839, GH840) Trevor James Smith
climpred v2.3.0 (2022-11-25)#
Note
As both maintainers moved out of academia into industry, this will be probably the last release for a while. If you are interested in maintaining climpred, please ping us.
Bug Fixes#
Fix
reference="persistence"for resampledinit. (GH730, GH731) Aaron Spring.HindcastEnsemble.verify()(comparison="m2o", reference="uninitialized", dim="init"). (GH735, GH731) Aaron Spring.HindcastEnsemble.remove_bias()does not drop single itemleaddimension. (GH771, GH773) Aaron Spring.
New Features#
Refactored
HindcastEnsemble.bootstrap()andPerfectModelEnsemble.bootstrap()based onHindcastEnsemble.verify()andPerfectModelEnsemble.verify(), which makes them more comparable.pers_sigis removed. Alsoreference=["climatology", "persistence"]skill has variance ifresample_dim='init'.bootstraprelies on eitherset_option(resample_skill_func="..."):"loop": callsclimpred.bootstrap.resample_skill_loop()which loops over iterations and callsverifyevery single time. Most understandable and stable, but slow."exclude_resample_dim_from_dim": callsclimpred.bootstrap.resample_skill_exclude_resample_dim_from_dim()which callsverify(dim=dim_without_resample_dim), resamples overresample_dimand then takes a mean overresample_dimif indim. EnablesHindcastEnsemble.bootstrap(resample_dim="init", alignment="same_verifs"). Fast alternative forresample_dim="init"."resample_before": callsclimpred.bootstrap.resample_skill_resample_before()which resamplesiterationdimension and then callsverifyvectorized. Fast alternative forresample_dim="member"."default":climpreddecides which to use
(relates to GH375, GH731) Aaron Spring.
climpred.set_option(resample_skill_func='exclude_resample_dim_from_dim')allowsHindcastEnsemble.bootstrap(alignment='same_verifs', resample_dim='init'). Does not work forpearson_r-derived metrics. (GH582, GH731) Aaron Spring.climpred.utils.convert_init_lead_to_valid_time_lead()convertsdata(init, lead)todata(valid_time, lead)to visualize predictability barrier and the reverseclimpred.utils.convert_valid_time_lead_to_init_lead(). (GH774, GH775, GH783) Aaron Spring.
Internals/Minor Fixes#
Refactor
asvbenchmarking. Addrun-benchmarkslabel toPRto runasvvia Github Actions. (GH664, GH718) Aaron Spring.Remove
ipythonfromrequirements.txt. (GH720) Aaron Spring.Calculating
np.isinonasi8instead ofxr.CFTimeIndexspeeds upHindcastEnsemble.verify()andHindcastEnsemble.bootstrap()with large number of inits. (GH414, GH724) Aaron Spring.Add option
bootstrap_resample_skill_funcfor they what skill is resampled inHindcastEnsemble.bootstrap()andPerfectModelEnsemble.bootstrap(), seeset_options. (GH731) Aaron Spring.Add option
resample_iterations_functo decide whetherxskillscore.resampling.resample_iterations()orxskillscore.resampling.resample_iterations()should be used, seeset_options. (GH731) Aaron Spring. - Add optionbootstrap_uninitialized_from_iterations_meanto exchangeuninitializedskill with the iteration meanuninitialized. Defaults to False., seeset_options. (GH731) Aaron Spring.alignment="same_verifs"will not result inNaN``s in ``valid_time. (GH777) Aaron Spring.HindcastEnsemble.plot_alignment()(return_xr=True)containsvalid_timecoordinate. (GH779) Aaron Spring.
Bug Fixes#
Fix
PerfectModel_persistence_from_initialized_lead_0=Truewith multiple references. (GH732, GH733) Aaron Spring.
Documentation#
Add verify dim example showing how
HindcastEnsemble.verify()andPerfectModelEnsemble.verify()are sensitive todimand howdimanswers different research questions. (GH740) Aaron Spring.
climpred v2.2.0 (2021-12-20)#
Bug Fixes#
Fix when creating
valid_timefromlead.attrs["units"]in["seasons", "years"]with multi-month stride ininit. (GH698, GH700) Aaron Spring.Fix
seasonality="season"inreference="climatology". (GH641, GH703) Aaron Spring.
New Features#
Upon instantiation,
PredictionEnsemblegenerates new 2-dimensional coordinatevalid_timeforinitializedfrominitandlead, which is matched withtimefromverificationduring alignment. (GH575, GH675, GH678) Aaron Spring.
>>> hind = climpred.tutorial.load_dataset("CESM-DP-SST")
>>> hind.lead.attrs["units"] = "years"
>>> climpred.HindcastEnsemble(hind).get_initialized()
<xarray.Dataset>
Dimensions: (lead: 10, member: 10, init: 64)
Coordinates:
* lead (lead) int32 1 2 3 4 5 6 7 8 9 10
* member (member) int32 1 2 3 4 5 6 7 8 9 10
* init (init) object 1954-01-01 00:00:00 ... 2017-01-01 00:00:00
valid_time (lead, init) object 1955-01-01 00:00:00 ... 2027-01-01 00:00:00
Data variables:
SST (init, lead, member) float64 ...
Allow
leadasfloatalso ifcalendar="360_day"orlead.attrs["units"]not in["years","seasons","months"]. (GH564, GH675) Aaron Spring.Implement
HindcastEnsemble.generate_uninitialized()resampling years without replacement frominitialized. (GH589, GH591) Aaron Spring.Implement Logarithmic Ensemble Skill Score
_less(). (GH239, GH687) Aaron Spring.HindcastEnsemble.remove_seasonality()andPerfectModelEnsemble.remove_seasonality()remove the seasonality of allclimpreddatasets. (GH530, GH688) Aaron Spring.Add keyword
groupbyinHindcastEnsemble.verify(),PerfectModelEnsemble.verify(),HindcastEnsemble.bootstrap()andPerfectModelEnsemble.bootstrap()to group skill by initializations seasonality. (GH635, GH690) Aaron Spring.
>>> import climpred
>>> hind = climpred.tutorial.load_dataset("NMME_hindcast_Nino34_sst")
>>> obs = climpred.tutorial.load_dataset("NMME_OIv2_Nino34_sst")
>>> hindcast = climpred.HindcastEnsemble(hind).add_observations(obs)
>>> # skill for each init month separated
>>> skill = hindcast.verify(
... metric="rmse",
... dim="init",
... comparison="e2o",
... skipna=True,
... alignment="maximize",
... groupby="month",
... )
>>> skill
<xarray.Dataset>
Dimensions: (month: 12, lead: 12, model: 12)
Coordinates:
* lead (lead) float64 0.0 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 9.0 10.0 11.0
* model (model) object 'NCEP-CFSv2' 'NCEP-CFSv1' ... 'GEM-NEMO'
skill <U11 'initialized'
* month (month) int64 1 2 3 4 5 6 7 8 9 10 11 12
Data variables:
sst (month, lead, model) float64 0.4127 0.3837 0.3915 ... 1.255 3.98
>>> skill.sst.plot(hue="model", col="month", col_wrap=3)
HindcastEnsemble.plot_alignment()shows how forecast and observations are aligned based on the alignment keyword. This may help understanding which dates are matched for the differentalignmentapproaches. (GH701, GH702) Aaron Spring.In [1]: from climpred.tutorial import load_dataset In [2]: hindcast = climpred.HindcastEnsemble( ...: load_dataset("CESM-DP-SST") ...: ).add_observations(load_dataset("ERSST")) ...: In [3]: hindcast.plot_alignment(edgecolor="w") Out[3]: <xarray.plot.facetgrid.FacetGrid at 0x7136e986ec80>
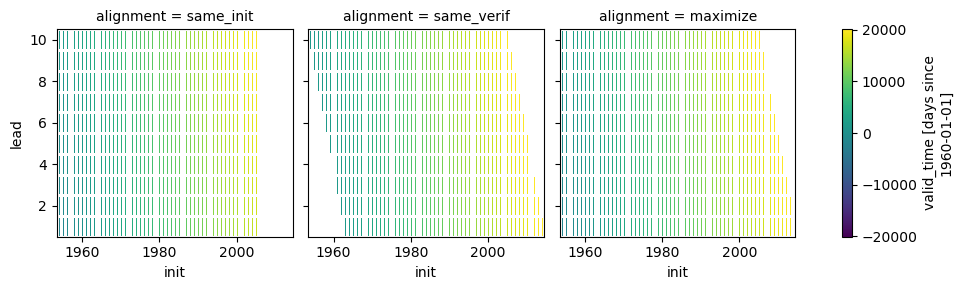
Add
attrsto newcoordinatescreated byclimpred. (GH695, GH697) Aaron Spring.Add
seasonality="weekofyear"inreference="climatology". (GH703) Aaron Spring.Compute
reference="persistence"inPerfectModelEnsemblefrominitializedfirstleadifset_options(PerfectModel_persistence_from_initialized_lead_0=True)(Falseby default) usingcompute_persistence_from_first_lead(). (GH637, GH706) Aaron Spring.
Internals/Minor Fixes#
Reduce dependencies. (GH686) Aaron Spring.
Add typing. (GH685, GH692) Aaron Spring.
refactor
add_attrsintoHindcastEnsemble.verify()andHindcastEnsemble.bootstrap(). Now all keywords are captured in the skill dataset attributes.attrs. (GH475, GH694) Aaron Spring.docstrings formatting with blackdocs. (GH708) Aaron Spring.
Documentation#
Refresh all docs with
sphinx_book_themeandmyst_nb. (GH707, GH708, GH709, GH710) Aaron Spring.
climpred v2.1.6 (2021-08-31)#
Adding on to v2.1.5, more bias reduction methods wrapped from
xclim
are implemented.
Bug Fixes#
Fix
results="p"inHindcastEnsemble.bootstrap()andPerfectModelEnsemble.bootstrap()whenreference='climatology'. (GH668, GH670) Aaron Spring.HindcastEnsemble.remove_bias()forhowin["modified_quantile", "basic_quantile", "gamma_mapping", "normal_mapping"]from bias_correction takes allmemberto create model distribution. (GH667) Aaron Spring.
New Features#
allow more bias reduction methods wrapped from xclim in
HindcastEnsemble.remove_bias():how="EmpiricalQuantileMapping":xclim.sdba.adjustment.EmpiricalQuantileMappinghow="DetrendedQuantileMapping":xclim.sdba.adjustment.DetrendedQuantileMappinghow="PrincipalComponents":xclim.sdba.adjustment.PrincipalComponentshow="QuantileDeltaMapping":xclim.sdba.adjustment.QuantileDeltaMappinghow="Scaling":xclim.sdba.adjustment.Scalinghow="LOCI":xclim.sdba.adjustment.LOCI
These methods do not respond to
OPTIONS['seasonality']like the other methods. Providegroup="init.month"to group by month orgroup='init'to skip grouping. Providegroup=Noneor skipgroupto useinit.{OPTIONS['seasonality']}. (GH525, GH662, GH666, GH671) Aaron Spring.
climpred v2.1.5 (2021-08-12)#
While climpred has used in the ASP summer colloquium 2021, many new features in HindcastEnsemble.remove_bias() were implemented.
Breaking changes#
renamed
cross_validatetocv=FalseinHindcastEnsemble.remove_bias(). Only used whentrain_test_split='unfair-cv'. (GH648, GH655). Aaron Spring.
Bug Fixes#
Shift back
initbyleadafterHindcastEnsemble.verify(). (GH644, GH645) Aaron Spring.
New Features#
HindcastEnsemble.remove_bias()accepts new keywordtrain_test_split='fair/unfair/unfair-cv'(defaultunfair) following Risbey et al. 2021. (GH648, GH655) Aaron Spring.allow more bias reduction methods in
HindcastEnsemble.remove_bias():how="additive_mean": correcting the mean forecast additively (already implemented)how="multiplicative_mean": correcting the mean forecast multiplicativelyhow="multiplicative_std": correcting the standard deviation multiplicatively
Wrapped from bias_correction:
how="modified_quantile": Bai et al. 2016how="basic_quantile": Themeßl et al. 2011how="gamma_mapping"andhow="normal_mapping": Switanek et al. 2017
HindcastEnsemble.remove_bias()now does leave-one-out cross validation when passingcv='LOO'andtrain_test_split='unfair-cv'.cv=Truefalls back tocv='LOO'. (GH643, GH646) Aaron Spring.Add new metrics
_spread()and_mul_bias()(GH638) Aaron Spring.Add new tutorial datasets: (GH651) Aaron Spring.
NMME_OIv2_Nino34_sstandNMME_hindcast_Nino34_sstwith monthly leadsObservations_GermanyandECMWF_S2S_Germanywith daily leads
Metadata from CF convenctions are automatically attached by cf_xarray. (GH639, GH656) Aaron Spring.
Raise warning when dimensions
time,initormemberare chunked to show user how to circumventxskillscorechunkingValueErrorwhen passing these dimensions asdiminHindcastEnsemble.verify()orHindcastEnsemble.bootstrap(). (GH509, GH658) Aaron Spring.Implement
PredictionEnsemble.chunks. (GH658) Aaron Spring.
Documentation#
Speed up ENSO monthly example with IRIDL server-side preprocessing (see context) (GH594, GH633) Aaron Spring.
Add CITATION.cff. Please cite Brady and Spring, 2020. (GH) Aaron Spring.
Use
NMME_OIv2_Nino34_sstandNMME_hindcast_Nino34_sstwith monthly leads for bias reduction demonstratingHindcastEnsemble.remove_bias(). (GH646) Aaron Spring.
climpred v2.1.4 (2021-06-28)#
New Features#
Allow
hours,minutesandsecondsaslead.attrs['units']. (GH404, GH603) Aaron Spring.Allow to set
seasonalityviaset_optionsto specify how to group inverify(reference='climatology'or inHindcastEnsemble.remove_bias(). (GH529, GH593, GH603) Aaron Spring.Allow
weekofyearviadatetimeinHindcastEnsemble.remove_bias(), but not yet implemented inverify(reference='climatology'). (GH529, GH603) Aaron Spring.Allow more dimensions in
initializedthan inobservations. This is particular useful if you have forecasts from multiple models (in amodeldimension) and want to verify against the same observations. (GH129, GH528, GH619) Aaron Spring.Automatically rename dimensions to
CLIMPRED_ENSEMBLE_DIMS["init","member","lead"] if CF standard_names in coordinate attributes match: (GH613, GH622) Aaron Spring."init":"forecast_reference_time""member":"realization""lead":"forecast_period"
If
leadcoordinate ispd.Timedelta,PredictionEnsembleconvertsleadcoordinate upon instantiation to integerleadand correspondinglead.attrs["units"]. (GH606, GH627) Aaron Spring.Require
xskillscore >= 0.0.20._rps()now works with differentcategory_edgesfor observations and forecasts, see daily ECMWF example. (GH629, GH630) Aaron Spring.Set options
warn_for_failed_PredictionEnsemble_xr_call,warn_for_rename_to_climpred_dims,warn_for_init_coords_int_to_annual,climpred_warningsviaset_options. (GH628, GH631) Aaron Spring.PredictionEnsembleacts likexarray.Datasetand understandsdata_vars,dims,sizes,coords,nbytes,equals,identical,__iter__,__len__,__contains__,__delitem__. (GH568, GH632) Aaron Spring.
Documentation#
Add documentation page about publicly available initialized datasets and corresponding `climpred examples <initialized-datasets.html>`_. (GH510, GH561, GH600) Aaron Spring.
Add GEFS example for numerical weather prediction. (GH602, GH603) Aaron Spring.
Add subseasonal daily ECMWF example using climetlab to access hindcasts from ECMWF cloud. (GH587, GH603) Aaron Spring.
Add subseasonal daily S2S example accessing S2S output on IRIDL with a cookie and working with “on-the-fly” reforecasts with
hdatedimension. (GH588, GH593) Aaron Spring.Added example climpred on GPU. Running
PerfectModelEnsemble.verify()on GPU with cupy-xarray finishes 10x faster. (GH592, GH607) Aaron Spring.How to work with biweekly aggregates in
climpred, see daily ECMWF example. (GH625, GH630) Aaron Spring.
Internals/Minor Fixes#
Add weekly upstream CI, which raises issues for failures. Adapted from
xarray. Manually trigger bygit commit -m '[test-upstream]'. Skip climpred_testing CI bygit commit -m '[skip-ci]'(GH518, GH596) Aaron Spring.
climpred v2.1.3 (2021-03-23)#
New Features#
HindcastEnsemble.verify(),PerfectModelEnsemble.verify(),HindcastEnsemble.bootstrap()andPerfectModelEnsemble.bootstrap()accept referenceclimatology. Furthermore, referencepersistencealso allows probabilistic metrics (GH202, GH565, GH566) Aaron Spring.Added new metric
_rocReceiver Operating Characteristic asmetric='roc'. (GH566) Aaron Spring.
Bug fixes#
HindcastEnsemble.verify()andHindcastEnsemble.bootstrap()acceptdimaslist,set,tupleorstr(GH519, GH558) Aaron Spring.PredictionEnsemble.map()now does not fail silently when applying a function to allxr.DatasetsofPredictionEnsemble. Instead,UserWarning``s are raised. Furthermore, ``PredictionEnsemble.map(func, *args, **kwargs)applies only function to Datasets with matching dims ifdim="dim0_or_dim1"is passed as**kwargs. (GH417, GH437, GH552) Aaron Spring._rpcwas fixed inxskillscore>=0.0.19and hence is not falsely limited to 1 anymore (GH562, GH566) Aaron Spring.
Internals/Minor Fixes#
Docstrings are now tested in GitHub actions continuous integration. (GH545, GH560) Aaron Spring.
Github actions now cancels previous commits, instead of running the full testing suite on every single commit. (GH560) Aaron Spring.
PerfectModelEnsemble.verify()does not add climpred attributes to skill by default anymore. (GH560) Aaron Spring.Drop
python==3.6support. (GH573) Aaron Spring.Notebooks are now linted with nb_black using
%load_ext nb_blackor%load_ext lab_blackfor Jupyter notebooks and Jupyter lab. (GH526, GH572) Aaron Spring.Reduce dependencies to install climpred. (GH454, GH572) Aaron Spring.
Examples from documentation available via Binder. Find further examples in the
examplesfolder. (GH549, GH578) Aaron Spring.Rename branch
mastertomain. (GH579) Aaron Spring.
climpred v2.1.2 (2021-01-22)#
This release is the fixed version for our Journal of Open Source Software (JOSS)
article about climpred, see review.
New Features#
Function to calculate predictability horizon
predictability_horizon()based on condition. (GH46, GH521) Aaron Spring.
Bug fixes#
PredictionEnsemble.smooth()now carrieslead.attrs(GH527, pr:521) Aaron Spring.PerfectModelEnsemble.verify()now works withreferencesalso for geospatial inputs, which returnedNaNbefore. (GH522, pr:521) Aaron Spring.PredictionEnsemble.plot()now shifts composite lead frequencies likedays,pentads,seasonscorrectly. (GH532, GH533) Aaron Spring.Adapt to
xesmf>=0.5.2for spatial xesmf smoothing. (GH543, GH548) Aaron Spring.HindcastEnsemble.remove_bias()now carries attributes. (GH531, GH551) Aaron Spring.
climpred v2.1.1 (2020-10-13)#
Breaking changes#
This version introduces a lot of breaking changes. We are trying to overhaul climpred to have an intuitive API that also forces users to think about methodology choices when running functions. The main breaking changes we introduced are for HindcastEnsemble.verify() and PerfectModelEnsemble.verify(). Now, instead of assuming defaults for most keywords, we require the user to define metric, comparison, dim, and alignment (for hindcast systems). We also require users to designate the number of iterations for bootstrapping.
User now has to designate number of iterations with
iterations=...inHindcastEnsemble.bootstrap()(GH384, GH436) Aaron Spring and Riley X. Brady.Make
metric,comparison,dim, andalignmentrequired (previous defaultNone) arguments forHindcastEnsemble.verify()(GH384, GH436) Aaron Spring and Riley X. Brady.Metric
_brier_scoreand_threshold_brier_score()now requires callable keyword argumentlogicalinstead offunc(GH388) Aaron Spring.HindcastEnsemble.verify()does not correctdimautomatically tomemberfor probabilistic metrics. (GH282, GH407) Aaron Spring.Users can no longer add multiple observations to
HindcastEnsemble. This will make current and future development much easier on maintainers (GH429, GH453) Riley X. Brady.Standardize the names of the output coordinates for
PredictionEnsemble.verify()andPredictionEnsemble.bootstrap()toinitialized,uninitialized, andpersistence.initializedshowcases the metric result after comparing the initialized ensemble to the verification data;uninitializedwhen comparing the uninitialized (historical) ensemble to the verification data;persistenceis the evaluation of the persistence forecast (GH460, GH478, GH476, GH480) Aaron Spring.referencekeyword inHindcastEnsemble.verify()should be choosen from [uninitialized,persistence].historicalno longer works. (GH460, GH478, GH476, GH480) Aaron Spring.HindcastEnsemble.verify()returns noskilldimension ifreference=None(GH480) Aaron Spring.comparisonis not applied to uninitialized skill inHindcastEnsemble.bootstrap(). (GH352, GH418) Aaron Spring.
New Features#
This release is accompanied by a bunch of new features. Math operations can now be used with our PredictionEnsemble objects and their variables can be sub-selected. Users can now quick plot time series forecasts with these objects. Bootstrapping is available for HindcastEnsemble. Spatial dimensions can be passed to metrics to do things like pattern correlation. New metrics have been implemented based on Contingency tables. We now include an early version of bias removal for HindcastEnsemble.
Use math operations like
+-*/withHindcastEnsembleandPerfectModelEnsemble. See demo Arithmetic-Operations-with-PredictionEnsemble-Objects. (GH377) Aaron Spring.Subselect data variables from
PerfectModelEnsembleas fromxarray.Dataset:PredictionEnsemble[["var1", "var3"]](GH409) Aaron Spring.Plot all datasets in
HindcastEnsembleorPerfectModelEnsemblebyPredictionEnsemble.plot()if no other spatial dimensions are present. (GH383) Aaron Spring.Bootstrapping now available for
HindcastEnsembleasHindcastEnsemble.bootstrap(), which is analogous to thePerfectModelEnsemblemethod. (GH257, GH418) Aaron Spring.HindcastEnsemble.verify()allows all dimensions frominitializedensemble asdim. This allows e.g. spatial dimensions to be used for pattern correlation. Make sure to useskipna=Truewhen using spatial dimensions and output has NaNs (in the case of land, for instance). (GH282, GH407) Aaron Spring.Allow binary forecasts at when calling
HindcastEnsemble.verify(), rather than needing to supply binary results beforehand. In other words,hindcast.verify(metric='bs', comparison='m2o', dim='member', logical=logical)is now the same ashindcast.map(logical).verify(metric='brier_score', comparison='m2o', dim='member'. (GH431) Aaron Spring.Check
calendartypes when usingHindcastEnsemble.add_observations(),HindcastEnsemble.add_uninitialized(),PerfectModelEnsemble.add_control()to ensure that the verification data calendars match that of the initialized ensemble. (GH300, GH452, GH422, GH462) Riley X. Brady and Aaron Spring.Implement new metrics which have been ported over from csiro-dcfp/doppyo to
xskillscoreby Dougie Squire. (GH439, GH456) Aaron Springrank histogram
_rank_histogram()discrimination
_discrimination()reliability
_reliability()ranked probability score
_rps()contingency table and related scores
_contingency()
Perfect Model
PerfectModelEnsemble.verify()no longer requirescontrolinPerfectModelEnsemble. It is only required whenreference=['persistence']. (GH461) Aaron Spring.Implemented bias removal
remove_bias.remove_bias(how='mean')removes the mean bias of initialized hindcasts with respect to observations. See example. (GH389, GH443, GH459) Aaron Spring and Riley X. Brady.
Depreciated#
spatial_smoothing_xrcoarsenno longer used for spatial smoothing. (GH391) Aaron Spring.compute_metric,compute_uninitializedandcompute_persistenceno longer in use forPerfectModelEnsemblein favor ofPerfectModelEnsemble.verify()with thereferencekeyword instead. (GH436, GH468, GH472) Aaron Spring and Riley X. Brady.'historical'no longer a valid choice forreference. Use'uninitialized'instead. (GH478) Aaron Spring.
Bug Fixes#
PredictionEnsemble.verify()andPredictionEnsemble.bootstrap()now acceptmetric_kwargs. (GH387) Aaron Spring.PerfectModelEnsemble.verify()now accepts'uninitialized'as a reference. (GH395) Riley X. Brady.Spatial and temporal smoothing
PredictionEnsemble.smooth()now work as expected and rename time dimensions afterverify(). (GH391) Aaron Spring.PredictionEnsemble.verify(comparison='m2o', references=['uninitialized', 'persistence']does not fail anymore. (GH385, GH400) Aaron Spring.Remove bias using
dayofyearinHindcastEnsemble.reduce_bias(). (GH443) Aaron Spring.climpredworks withdask=>2.28. (GH479, GH482) Aaron Spring.
Documentation#
Updates
climpredtagline to “Verification of weather and climate forecasts.” (GH420) Riley X. Brady.Adds section on how to use arithmetic with
HindcastEnsemble. (GH378) Riley X. Brady.Add docs section for similar open-source forecasting packages. (GH432) Riley X. Brady.
Add all metrics to main API in addition to metrics page. (GH438) Riley X. Brady.
Add page on bias removal Aaron Spring.
Internals/Minor Fixes#
PredictionEnsemble.verify()replaces deprecatedPerfectModelEnsemble.compute_metric()and acceptsreferenceas keyword. (GH387) Aaron Spring.Cleared out unnecessary statistics functions from
climpredand migrated them toesmtools. Addesmtoolsas a required package. (GH395) Riley X. Brady.Remove fixed pandas dependency from
pandas=0.25to stablepandas. (GH402, GH403) Aaron Spring.dimis expected to be a list of strings incompute_perfect_model()and ~climpred.prediction.compute_hindcast. (GH282, GH407) Aaron Spring.Update
cartopyrequirement to 0.0.18 or greater to release lock onmatplotlibversion. Updatexskillscorerequirement to 0.0.18 to cooperate with newxarrayversion. (GH451, GH449) Riley X. BradySwitch from Travis CI and Coveralls to Github Actions and CodeCov. (GH471) Riley X. Brady
Assertion functions added for
PerfectModelEnsemble:assert_PredictionEnsemble(). (GH391) Aaron Spring.Test all metrics against synthetic data. (GH388) Aaron Spring.
climpred v2.1.0 (2020-06-08)#
Breaking Changes#
Keyword
bootstraphas been replaced withiterations. We feel that this more accurately describes the argument, since “bootstrap” is really the process as a whole. (GH354) Aaron Spring.
New Features#
HindcastEnsembleandPerfectModelEnsemblenow use an HTML representation, following the more recent versions ofxarray. (GH371) Aaron Spring.HindcastEnsemble.verify()now takesreference=...keyword. Current options are'persistence'for a persistence forecast of the observations and'uninitialized'for an uninitialized/historical reference, such as an uninitialized/forced run. (GH341) Riley X. Brady.We now only enforce a union of the initialization dates with observations if
reference='persistence'forHindcastEnsemble. This is to ensure that the same set of initializations is used by the observations to construct a persistence forecast. (GH341) Riley X. Brady.compute_perfect_model()now accepts initialization (init) ascftimeandint.cftimeis now implemented into the bootstrap uninitialized functions for the perfect model configuration. (GH332) Aaron Spring.New explicit keywords in bootstrap functions for
resampling_dimandreference_compute(GH320) Aaron Spring.Logging now included for
compute_hindcastwhich displays theinitsand verification dates used at each lead (GH324) Aaron Spring, (GH338) Riley X. Brady. See (logging).New explicit keywords added for
alignmentof verification dates and initializations. (GH324) Aaron Spring. See (alignment)'maximize': Maximize the degrees of freedom by slicinghindandverifto a common time frame at each lead. (GH338) Riley X. Brady.'same_inits': slice to a common init frame prior to computing metric. This philosophy follows the thought that each lead should be based on the same set of initializations. (GH328) Riley X. Brady.'same_verifs': slice to a common/consistent verification time frame prior to computing metric. This philosophy follows the thought that each lead should be based on the same set of verification dates. (GH331) Riley X. Brady.
Performance#
The major change for this release is a dramatic speedup in bootstrapping functions, led by Aaron Spring. We focused on scalability with dask and found many places we could compute skill simultaneously over all bootstrapped ensemble members rather than at each iteration.
Bootstrapping uninitialized skill in the perfect model framework is now sped up significantly for annual lead resolution. (GH332) Aaron Spring.
General speedup in
~climpred.bootstrap.bootstrap_hindcastand~climpred.bootstrap.bootstrap_perfect_model: (GH285) Aaron Spring.Properly implemented handling for lazy results when inputs are chunked.
User gets warned when chunking potentially unnecessarily and/or inefficiently.
Bug Fixes#
Alignment options now account for differences in the historical time series if
reference='historical'. (GH341) Riley X. Brady.
Internals/Minor Fixes#
Added a Code of Conduct (GH285) Aaron Spring.
Gather
pytest.fixture in ``conftest.py. (GH313) Aaron Spring.Move
x_METRICSandCOMPARISONStometrics.pyandcomparisons.pyin order to avoid circular import dependencies. (GH315) Aaron Spring.asvbenchmarks added forHindcastEnsemble(GH285) Aaron Spring.Ignore irrelevant warnings in
pytestand mark slow tests (GH333) Aaron Spring.Default
CONCAT_KWARGSnow in allxr.concatto speed up bootstrapping. (GH330) Aaron Spring.Remove
membercoords form2ccomparison for probabilistic metrics. (GH330) Aaron Spring.Refactored
~climpred.prediction.compute_hindcastandcompute_perfect_model(). (GH330) Aaron Spring.Changed lead0 coordinate modifications to be compliant with
xarray=0.15.1incompute_persistence(). (GH348) Aaron Spring.Exchanged
my_quantilewithxr.quantile(skipna=False). (GH348) Aaron Spring.Remove
sigfromplot_bootstrapped_skill_over_leadyear(). (GH351) Aaron Spring.Require
xskillscore v0.0.15and use their functions for effective sample size-based metrics. (:pr: 353) Riley X. Brady.Faster bootstrapping without replacement used in threshold functions of
climpred.stats(GH354) Aaron Spring.Require
cftime v1.1.2, which modifies their object handling to create 200-400x speedups in some basic operations. (GH356) Riley X. Brady.Resample first and then calculate skill in ~climpred.bootstrap.bootstrap_perfect_model and ~climpred.bootstrap.bootstrap_hindcast (GH355) Aaron Spring.
Documentation#
Added demo to setup your own raw model output compliant to
climpred(GH296) Aaron Spring. See (here).Added demo using
intake-esmwithclimpred. See demo. (GH296) Aaron Spring.Added Verification Alignment page explaining how initializations are selected and aligned with verification data. (GH328) Riley X. Brady. See (here).
climpred v2.0.0 (2020-01-22)#
New Features#
Add support for
days,pentads,weeks,months,seasonsfor lead time resolution.climprednow requires aleadattribute “units” to decipher what resolution the predictions are at. (GH294) Kathy Pegion and Riley X. Brady.
HindcastEnsemblenow hasHindcastEnsemble.add_observations()andHindcastEnsemble.get_observations()methods. These are the same as.add_reference()and.get_reference(), which will be deprecated eventually. The name change clears up confusion, since “reference” is the appropriate name for a reference forecast, e.g."persistence". (GH310) Riley X. Brady.HindcastEnsemblenow has.verify()function, which duplicates the.compute_metric()function. We feel that.verify()is more clear and easy to write, and follows the terminology of the field. (GH310) Riley X. Brady.e2oandm2oare now the preferred keywords for comparing hindcast ensemble means and ensemble members to verification data, respectively. (GH310) Riley X. Brady.
Documentation#
New example pages for subseasonal-to-seasonal prediction using
climpred. (GH294) Kathy PegionComparisons page rewritten for more clarity. (GH310) Riley X. Brady.
Bug Fixes#
Fixed m2m broken comparison issue and removed correction. (GH290) Aaron Spring.
Internals/Minor Fixes#
Updates to
xskillscorev0.0.12 to get a 30-50% speedup in compute functions that rely on metrics from there. (GH309) Riley X. Brady.Stacking dims is handled by
comparisons, no need for internal keywordstack_dims. Thereforecomparisonnow takesmetricas argument instead. (GH290) Aaron Spring.assign_attrsnow carries dim (GH290) Aaron Spring.referencechanged toverifthroughout hindcast compute functions. This is more clear, sincereferenceusually refers to a type of forecast, such as persistence. (GH310) Riley X. Brady.Comparisonobjects can now have aliases. (GH310) Riley X. Brady.
climpred v1.2.1 (2020-01-07)#
Depreciated#
madno longer a keyword for the median absolute error metric. Users should now usemedian_absolute_error, which is identical to changes inxskillscoreversion 0.0.10. (GH283) Riley X. Bradypaccno longer a keyword for the p value associated with the Pearson product-moment correlation, since it is used by the correlation coefficient. (GH283) Riley X. Bradymsssno longer a keyword for the Murphy’s MSSS, since it is reserved for the standard MSSS. (GH283) Riley X. Brady
New Features#
Metrics
pearson_r_eff_p_valueandspearman_r_eff_p_valueaccount for autocorrelation in computing p values. (GH283) Riley X. BradyMetric
effective_sample_sizecomputes number of independent samples between two time series being correlated. (GH283) Riley X. BradyAdded keywords for metrics: (GH283) Riley X. Brady
'pval'forpearson_r_p_value['n_eff', 'eff_n']foreffective_sample_size['p_pval_eff', 'pvalue_eff', 'pval_eff']forpearson_r_eff_p_value['spvalue', 'spval']forspearman_r_p_value['s_pval_eff', 'spvalue_eff', 'spval_eff']forspearman_r_eff_p_value'nev'fornmse
Internals/Minor Fixes#
climprednow requiresxarrayversion 0.14.1 so that thedrop_vars()keyword used in our package does not throw an error. (GH276) Riley X. BradyUpdate to
xskillscoreversion 0.0.10 to fix errors in weighted metrics with pairwise NaNs. (GH283) Riley X. Bradydoc8added topre-committo have consistent formatting on.rstfiles. (GH283) Riley X. BradyRemove
properattribute onMetricclass since it isn’t used anywhere. (GH283) Riley X. BradyAdd testing for effective p values. (GH283) Riley X. Brady
Add testing for whether metric aliases are repeated/overwrite each other. (GH283) Riley X. Brady
pppchanged tomsess, but keywords allow forpppandmsssstill. (GH283) Riley X. Brady
Documentation#
Expansion of metrics documentation with much more detail on how metrics are computed, their keywords, references, min/max/perfect scores, etc. (GH283) Riley X. Brady
Update terminology page with more information on metrics terminology. (GH283) Riley X. Brady
climpred v1.2.0 (2019-12-17)#
Depreciated#
Abbreviation
pvaldepreciated. Usep_pvalforpearson_r_p_valueinstead. (GH264) Aaron Spring.
New Features#
Users can now pass a custom
metricorcomparisonto compute functions. (GH268) Aaron Spring.New deterministic metrics (see metrics). (GH264) Aaron Spring.
Spearman ranked correlation (spearman_r)
Spearman ranked correlation p-value (spearman_r_p_value)
Mean Absolute Deviation (mad)
Mean Absolute Percent Error (mape)
Symmetric Mean Absolute Percent Error (smape)
Users can now apply arbitrary
xarraymethods toHindcastEnsembleandPerfectModelEnsemble. (GH243) Riley X. Brady.Add “getter” methods to
HindcastEnsembleandPerfectModelEnsembleto retrievexarraydatasets from the objects. (GH243) Riley X. Brady.
>>> hind = climpred.tutorial.load_dataset("CESM-DP-SST")
>>> ref = climpred.tutorial.load_dataset("ERSST")
>>> hindcast = climpred.HindcastEnsemble(hind)
>>> hindcast = hindcast.add_reference(ref, "ERSST")
>>> print(hindcast)
<climpred.HindcastEnsemble>
Initialized Ensemble:
SST (init, lead, member) float64 ...
ERSST:
SST (time) float32 ...
Uninitialized:
None
>>> print(hindcast.get_initialized())
<xarray.Dataset>
Dimensions: (init: 64, lead: 10, member: 10)
Coordinates:
* lead (lead) int32 1 2 3 4 5 6 7 8 9 10
* member (member) int32 1 2 3 4 5 6 7 8 9 10
* init (init) float32 1954.0 1955.0 1956.0 1957.0 ... 2015.0 2016.0 2017.0
Data variables:
SST (init, lead, member) float64 ...
>>> print(hindcast.get_reference("ERSST"))
<xarray.Dataset>
Dimensions: (time: 61)
Coordinates:
* time (time) int64 1955 1956 1957 1958 1959 ... 2011 2012 2013 2014 2015
Data variables:
SST (time) float32 ...
metric_kwargscan be passed toMetric. (GH264) Aaron Spring.See
metric_kwargsunder metrics.
Bug Fixes#
HindcastEnsemble.compute_metric()doesn’t drop coordinates from the initialized hindcast ensemble anymore. (GH258) Aaron Spring.Metric
uaccdoes not crash whenpppnegative anymore. (GH264) Aaron Spring.Update
xskillscoreto version 0.0.9 to fix all-NaN issue withpearson_randpearson_r_p_valuewhen there’s missing data. (GH269) Riley X. Brady.
Internals/Minor Fixes#
Rewrote
varweighted_mean_period()based onxrft. Changedtime_dimtodim. Function no longer drops coordinates. (GH258) Aaron SpringAdd
dim='time'indpp(). (GH258) Aaron SpringComparisons
m2m,m2erewritten to not stack dims into supervector because this is now done inxskillscore. (GH264) Aaron SpringAdd
tqdmprogress bar tobootstrap_compute(). (GH244) Aaron SpringRemove inplace behavior for
HindcastEnsembleandPerfectModelEnsemble. (GH243) Riley X. BradyAdded tests for chunking with
dask. (GH258) Aaron SpringFix test issues with esmpy 8.0 by forcing esmpy 7.1 (GH269). Riley X. Brady
Rewrote
metricsandcomparisonsas classes to accomodate custom metrics and comparisons. (GH268) Aaron Spring
Documentation#
Add examples notebook for temporal and spatial smoothing. (GH244) Aaron Spring
Add documentation for computing a metric over a specified dimension. (GH244) Aaron Spring
Update API to be more organized with individual function/class pages. (GH243) Riley X. Brady.
Add page describing the
HindcastEnsembleandPerfectModelEnsembleobjects more clearly. (GH243) Riley X. BradyAdd page for publications and helpful links. (GH270) Riley X. Brady.
climpred v1.1.0 (2019-09-23)#
Features#
Write information about skill computation to netcdf attributes(GH213) Aaron Spring
Temporal and spatial smoothing module (GH224) Aaron Spring
Add metrics brier_score, threshold_brier_score and crpss_es (GH232) Aaron Spring
Allow compute_hindcast and compute_perfect_model to specify which dimension dim to calculate metric over (GH232) Aaron Spring
Bug Fixes#
Correct implementation of probabilistic metrics from xskillscore in compute_perfect_model, bootstrap_perfect_model, compute_hindcast and bootstrap_hindcast, now requires xskillscore>=0.05 (GH232) Aaron Spring
Internals/Minor Fixes#
Rename .stats.DPP to dpp (GH232) Aaron Spring
Add matplotlib as a main dependency so that a direct pip installation works (GH211) Riley X. Brady.
climpredis now installable from conda-forge (GH212) Riley X. Brady.Fix erroneous descriptions of sample datasets (GH226) Riley X. Brady.
Benchmarking time and peak memory of compute functions with asv (GH231) Aaron Spring
Documentation#
Add scope of package to docs for clarity for users and developers. (GH235) Riley X. Brady.
climpred v1.0.1 (2019-07-04)#
Bug Fixes#
Accomodate for lead-zero within the
leaddimension (GH196) Riley X. Brady.Fix issue with adding uninitialized ensemble to
HindcastEnsembleobject (GH199) Riley X. Brady.Allow
max_dofkeyword to be passed tocompute_metricandcompute_persistenceforHindcastEnsemble. (GH199) Riley X. Brady.
Internals/Minor Fixes#
Force
xskillscoreversion 0.0.4 or higher to avoidImportError(GH204) Riley X. Brady.Change
max_dfskeyword tomax_dof(GH199) Riley X. Brady.Add tests for
HindcastEnsembleandPerfectModelEnsemble. (GH199) Riley X. Brady
climpred v1.0.0 (2019-07-03)#
climpred v1.0.0 represents the first stable release of the package. It includes
HindcastEnsemble and PerfectModelEnsemble objects to
perform analysis with.
It offers a suite of deterministic and probabilistic metrics that are optimized to be
run on single time series or grids of data (e.g., lat, lon, and depth). Currently,
climpred only supports annual forecasts.
Features#
Bootstrap prediction skill based on resampling with replacement consistently in
ReferenceEnsembleandPerfectModelEnsemble. (GH128) Aaron SpringConsistent bootstrap function for
climpred.statsfunctions viabootstrap_funcwrapper. (GH167) Aaron Springmany more metrics:
_msss_murphy,_lessand probabilistic_crps,_crpss(GH128) Aaron Spring
Bug Fixes#
compute_uninitializednow trims input data to the same time window. (GH193) Riley X. Bradyrm_polynow properly interpolates/fills NaNs. (GH192) Riley X. Brady
Internals/Minor Fixes#
The
climpredversion can be printed. (GH195) Riley X. BradyConstants are made elegant and pushed to a separate module. (GH184) Andrew Huang
Checks are consolidated to their own module. (GH173) Andrew Huang
Documentation#
Documentation built extensively in multiple PRs.
climpred v0.3 (2019-04-27)#
climpred v0.3 really represents the entire development phase leading up to the
version 1 release. This was done in collaboration between Riley X. Brady,
Aaron Spring, and Andrew Huang. Future releases will have less additions.
Features#
Introduces object-oriented system to
climpred, with classesReferenceEnsembleandPerfectModelEnsemble. (GH86) Riley X. BradyExpands bootstrapping module for perfect-module configurations. (GH78, GH87) Aaron Spring
Adds functions for computing Relative Entropy (GH73) Aaron Spring
Sets more intelligible dimension expectations for
climpred(GH98, GH105) Riley X. Brady and Aaron Spring:init: initialization dates for the prediction ensemblelead: retrospective forecasts from prediction ensemble; returned dimension for prediction calculationstime: time dimension for control runs, references, etc.member: ensemble member dimension.
Updates
open_datasetto display available dataset names when no argument is passed. (GH123) Riley X. BradyChange
ReferenceEnsembletoHindcastEnsemble. (GH124) Riley X. BradyAdd probabilistic metrics to
climpred. (GH128) Aaron SpringConsolidate separate perfect-model and hindcast functions into singular functions (GH128) Aaron Spring
Add option to pass proxy through to
open_datasetfor firewalled networks. (GH138) Riley X. Brady
Bug Fixes#
xr_rm_polycan now operate on Datasets and with multiple variables. It also interpolates across NaNs in time series. (GH94) Andrew HuangTravis CI,
treon, andpytestall run for automated testing of new features. (GH98, GH105, GH106) Riley X. Brady and Aaron SpringClean up
check_xarraydecorators and make sure that they work. (GH142) Andrew HuangEnsures that
help()returns proper docstring even with decorators. (GH149) Andrew HuangFixes bootstrap so p values are correct. (GH170) Aaron Spring
Internals/Minor Fixes#
Adds unit testing for all perfect-model comparisons. (GH107) Aaron Spring
Updates CESM-LE uninitialized ensemble sample data to have 34 members. (GH113) Riley X. Brady
Adds MPI-ESM hindcast, historical, and assimilation sample data. (GH119) Aaron Spring
Replaces
check_xarraywith a decorator for checking that input arguments are xarray objects. (GH120) Andrew HuangAdd custom exceptions for clearer error reporting. (GH139) Riley X. Brady
Remove “xr” prefix from stats module. (GH144) Riley X. Brady
Add codecoverage for testing. (GH152) Riley X. Brady
Update exception messages for more pretty error reporting. (GH156) Andrew Huang
Add
pre-commitandflake8/blackcheck in CI. (GH163) Riley X. BradyChange
loadutilsmodule totutorialandopen_datasettoload_dataset. (GH164) Riley X. BradyRemove predictability horizon function to revisit for v2. (GH165) Riley X. Brady
Increase code coverage through more testing. (GH167) Aaron Spring
Consolidates checks and constants into modules. (GH173) Andrew Huang
climpred v0.2 (2019-01-11)#
Name changed to climpred, developed enough for basic decadal prediction tasks on a perfect-model ensemble and reference-based ensemble.
climpred v0.1 (2018-12-20)#
Collaboration between Riley Brady and Aaron Spring begins.